

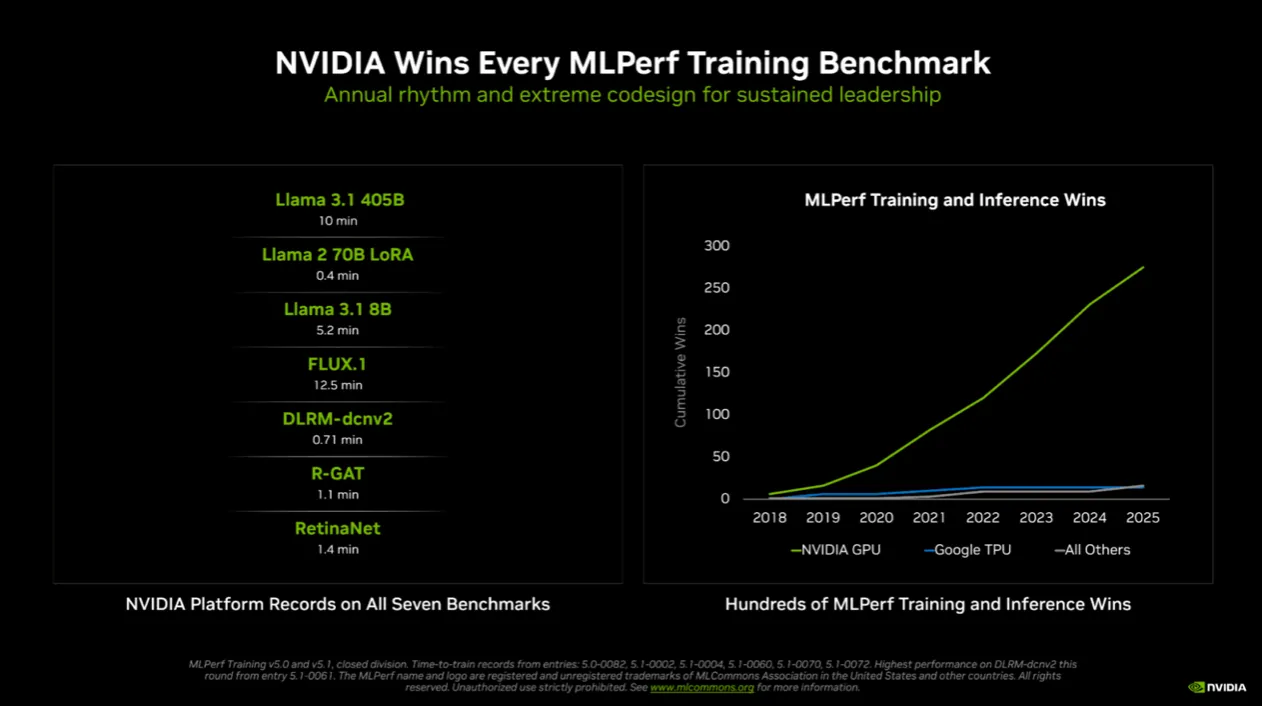
此次首次登场的 NVIDIA Blackwell Ultra GPU,搭载于 GB300 NVL72 机架级系统,在 MLPerf Training 即展现惊人能量。该平台先前已于 MLPerf Inference 创下纪录,本轮在训练端再度刷新多项表现。
相较上一代 Hopper,Blackwell Ultra 拥有跨世代强化的架构设计,Llama 3.1 405B 预训练效能提升超过 4 倍,Llama 2 70B LoRa 微调效能提升近 5 倍。
其中,关键包含全新 Tensor Core、可达 15 petaflops NVFP4 运算能力、注意力层吞吐效能翻倍与高达 279GB HBM3e 记忆体配备,使其能充分释放 FP4 训练模式的潜能。搭配全新 NVIDIA Quantum-X800 InfiniBand 网路平台,横向扩展频宽也比上一代翻倍。
本轮 MLPerf 最大亮点,是 NVIDIA 首度以 FP4(NVFP4)精度投入训练基准测试,并成功通过所有精度要求,树立业界第一个以 FP4 完成基准测试的平台。
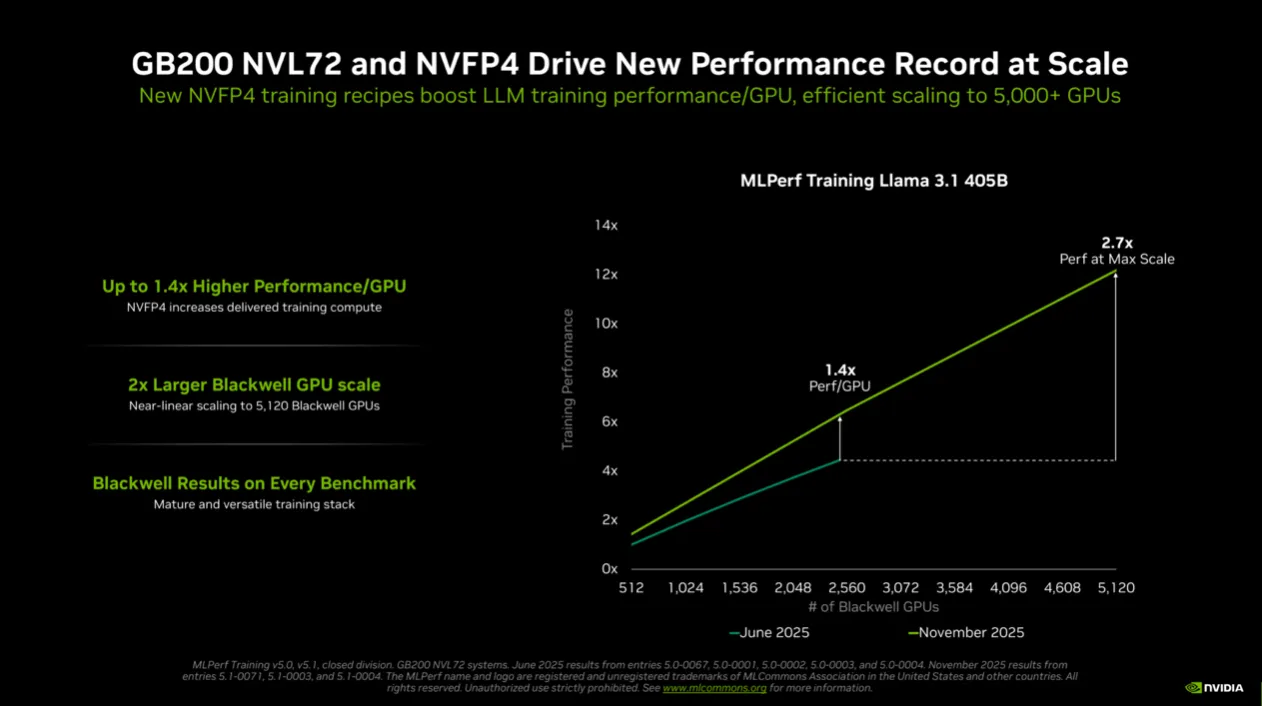
FP4 的核心价值,是以更少位元表示资料、降低运算负载,进而提升训练速度。然而低精度训练牵涉模型稳定性与准确度挑战。NVIDIA 在架构、软体堆叠与训练流程多层创新,使 FP4 运算速度达到 FP8 的两倍;Blackwell Ultra 更将此效能提升至三倍,为大型语言模型训练带来革命级加速。
NVIDIA 在本轮测试中以超过 5,000 颗 Blackwell GPU 同步协作,在 Llama 3.1 405B 测试中创下仅需 10 分钟训练完成的新里程碑,较上一轮最佳成绩提升达 2.7 倍。同时,NVIDIA 也展示 GPU 数量线性扩展效益:使用 2,560 颗 Blackwell GPU 时,训练耗时缩短至 18.79 分钟,比上一轮使用相近 GPU 数量的表现快上 45%,显示 FP4 精度与 Blackwell GPU 架构的强力互补性。

MLPerf Training 本轮新增两项基准测试:Llama 3.1 8B 与先进图像生成模型 FLUX.1。NVIDIA 再次包办最快纪录,包括:
使用 512 颗 Blackwell Ultra GPU 完成 Llama 3.1 8B 训练,仅 5.2 分钟。
使用 1,152 颗 Blackwell GPU 完成 FLUX.1 训练,仅 12.5 分钟。
值得注意的是,FLUX.1 只有 NVIDIA 提交结果,再度说明其在生成式 AI 训练的独有优势。
本轮 MLPerf 不仅由 NVIDIA 主导,更展现其庞大 AI 生态系的实力。包括 ASUS、Dell Technologies、技钢科技(GIGABYTE)、HPE、Krai、Lambda、Lenovo、Nebius、云达科技(QCT)、Supermicro、佛罗里达大学(University of Florida)、Verda(原 DataCrunch)、纬颖(WiWynn)等 15 家合作伙伴皆提交了多项亮眼成绩,显示 NVIDIA 平台已成全球主流 AI 训练解决方案,各大云端、研究机构与伺服器供应商皆在加速导入。
NVIDIA 表示,未来将以一年一更新的速度,持续提升预训练、后训练与推论表现,推动 AI 加速走向更智慧、更强大的下一个时代。
 點擊閱讀下一則新聞
點擊閱讀下一則新聞




