

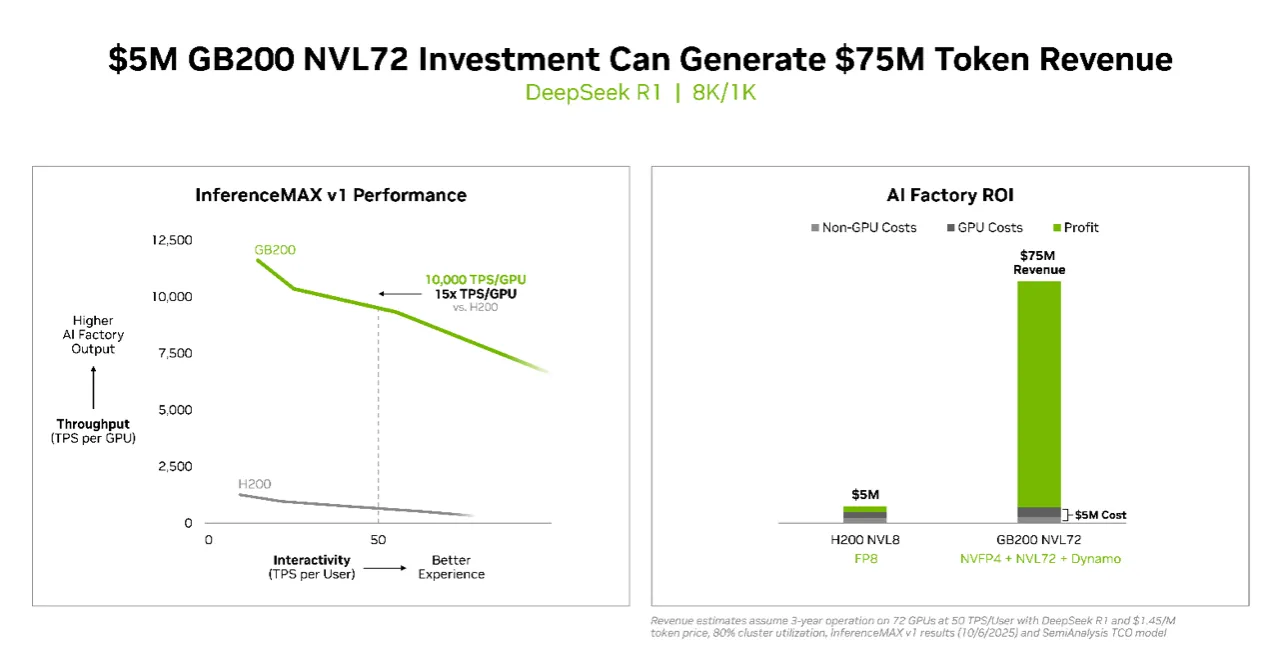
根据测试结果,投资500万美元于 NVIDIA GB200 NVL72 系统,可创造高达7,500万美元的词元(token)收益,投资报酬率高达15倍,开启推论运算的新经济模式,也凸显辉达在AI基础设施领域的领先优势。
Token为大型语言模型(LLM)处理文本的最小运算单位,是AI理解与生成语言的基本构成,每个token可能代表一个字、一个词或符号。随著AI推论需求激增,token生成速度与成本已成为衡量AI运算效能与经济价值的核心指标,反映资料中心在能源效率、系统架构与演算法优化间的综合竞争力。
InferenceMAX v1 由产业研究机构SemiAnalysis发布,是首个在真实应用场景中评估总运算成本的独立基准。NVIDIA超大规模与高效能运算副总裁Ian Buck指出,推论是AI每天创造价值的关键,这份结果证明NVIDIA的全端架构能同时兼顾效能与效率,协助客户在大规模AI部署下仍保持经济效益。该测试于多个热门模型上运行,证明现代AI已不仅追求速度,更重视经济规模与能源利用率。
随著生成式AI模型逐步进化至多步推理与工具整合,每次查询所产生的词元数急剧增加,也使推论效能与成本控制成为业界焦点。NVIDIA与OpenAI(gpt-oss 120B)、Meta(Llama 3 70B)及DeepSeek AI(DeepSeek R1)等开源团队合作,确保最新模型能针对全球最大规模的AI推论基础设施最佳化,展现其对开放生态系的长期承诺与技术主导地位。
在软体层面,NVIDIA持续以「硬体与软体协同设计」推升效能。gpt-oss-120B模型在搭载 TensorRT-LLM 函式库 的DGX Blackwell B200系统上,展现业界领先的推论表现。TensorRT-LLM v1.0的推出,更推动大型AI模型在反应速度与吞吐量上的重大突破。借由 NVLink Switch 1,800 GB/s 双向频宽,NVIDIA成功让gpt-oss-120B效能再提升数倍,而新版本gpt-oss-120b-Eagle3-v2导入「推测式解码(speculative decoding)」技术,使每使用者输送量提升三倍,达到每秒100词元的处理速度。
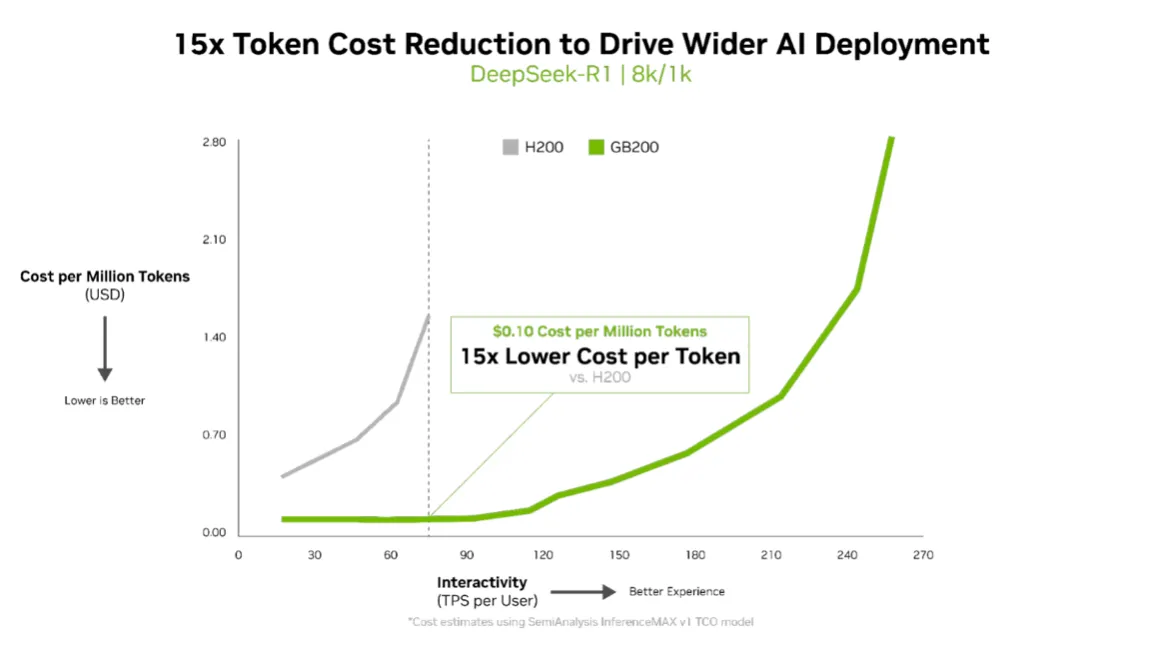
针对Llama 3.3 70B等大型模型,NVIDIA Blackwell B200在InferenceMAX v1测试中再创新标准。每GPU可达10,000 TPS(每秒交易量),每使用者达50 TPS的互动性能,比上一代H200提升四倍输送量。对于功率受限的AI工厂而言,Blackwell架构每兆瓦输送量较上一代提升十倍,每百万词元成本降低十五倍,充分展现推论经济性的跃进。
InferenceMAX采用帕雷托前沿(Pareto frontier)分析法,评估资料中心在输送量、能源效率与回应性间的最佳平衡。这不仅是一项效能数据展示,更代表NVIDIA Blackwell在真实生产环境中能同时实现高效能与高投资报酬率。
NVIDIA指出,Blackwell架构整合 NVFP4低精度格式、第五代NVLink并行连结 与多项开源推论框架,打造为速度、效率与规模而生的全端平台。自发表以来,仅透过软体更新便已让效能翻倍以上。
随著AI从试点走向AI工厂时代,InferenceMAX v1的出现,协助企业在「每词元成本」「延迟性服务水准协议」与「动态工作负载」之间找到最优配置。NVIDIA强调,透过 Think SMART 架构,企业能将效能直接转化为收益,实现推论投资最大化,开启AI经济效益的新纪元。
 點擊閱讀下一則新聞
點擊閱讀下一則新聞




